Update #7
12 Nov 2018TREC Questions Classification
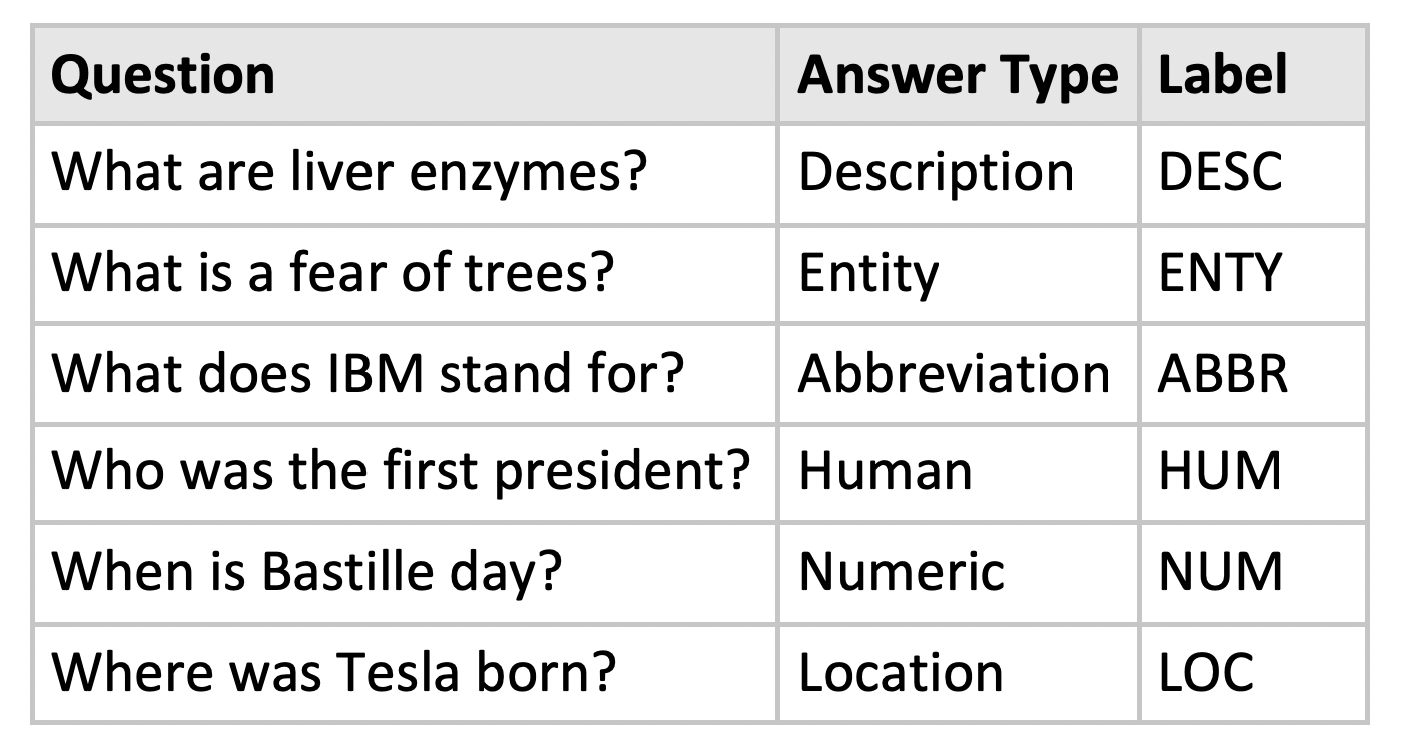
The Text Retrieval Conference (TREC) Questions Classification dataset [Voorheas, 2000] is one of many downstream NLP tasks used to evaluate sentence embeddings. It consists of 5,452 training and 500 test questions organised into one of six categories:
Sentence embeddings
Google’s Universal Sentence Encoder [Cer, 2018] was used to embed the questions into 512-dimensional vectors. The encoder seeks to embed sentences into a vector space whilst preserving semantic similarities, which can then be used for downstream NLP tasks.
Using t-SNE, we can visualise the vectors in a 2D graph (explore clusters by hovering over with your cursor). Some observations can be made:
- Questions with similar semantics are clustered together. For example, the cluster in the center left relates to questions about fear. The clustering occurs regardless of the ground truth labels.
- Clustering by semantics naturally yields some extent of clustering by answer type.
Why are questions not clustered according to answer type?
When you stop to think, the answer becomes obvious. At this stage, we have not yet incorporated any knowledge of the classification task and ground truth labels. The vectors purely encode for the semantic information in the sentence, thus t-SNE yields clusters of similar semantics.
What makes two things similar?
One of the main goals of visualisation or clustering is to group similar items and separate dissimilar items. But the concept of similarity is not fixed; it depends largely on context.
For instance, consider three different movies:
- Terminator
- Die Hard
- Titanic
Terminator and Die Hard are clearly similar because they are both action movies. But in another context, Terminator is also similar to Titanic - they are both directed by James Cameron. Similarity depends on context.
Training a question classifier on TREC
The same phenomenon occurs in NLP as well. Consider now three questions:
- Why are haunted houses popular?
- What is a fear of thunder? (Entity answer type)
- What animal has the best hearing? (Entity answer type)
In the graph above, questions 1&2 are clustered together because they have the same semantics. But for the sake of our classification task, we want 2&3 to be clustered together. What we need is embeddings which are task-specific.
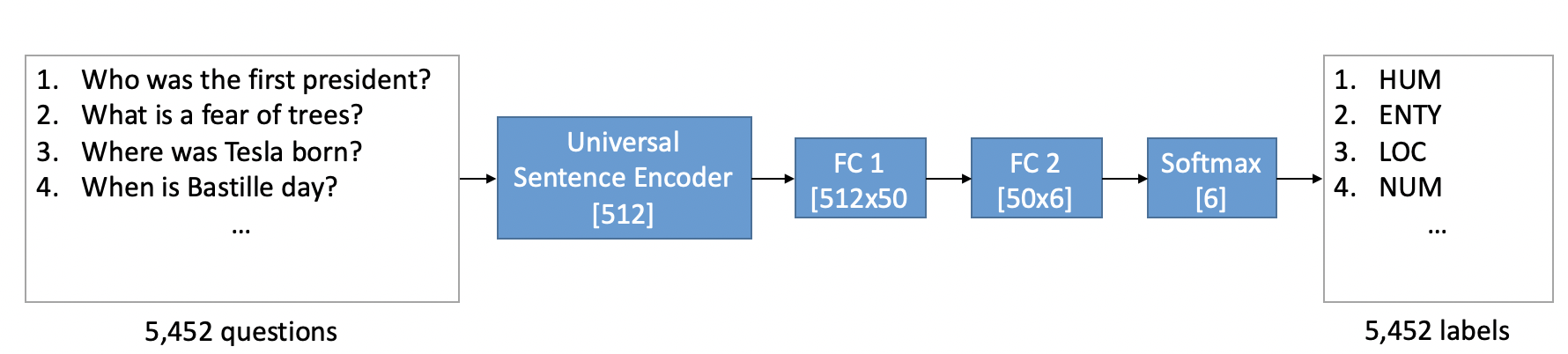
For this, a multi-layer perceptron (MLP) with a single hidden layer of size 50 was trained following [Perone, 2018]. The MLP yields a classification accuracy of 90% on the test set.
Now, we perform t-SNE on the 50-dimensional features extracted from the hidden layer.
As expected, we can now observe clusters according to the answer type. An important insight comes forth:
Supervised training yields task-specific representations.
This phenomenon is well understood in the field of computer vision [Yosinki, 2014]. In deep CNNs, the first layers act as Gabor filters or edge detectors, while the later layers detect higher-level features or entire parts such as eyes. The transition of network features from general to task-specific allows for transfer learning.
When we perform data visualisation or clustering, we should remind ourselves of the context.
- When do we say that two things are similar?
- What do the feature vectors represent?
- Are the vector representations consistent with the chosen definition of similarity?