Inductive Biases
06 Oct 2019What is an inductive bias?
In everyday life, we hold certain inductive beliefs (eg spatial/temporal smoothness) so that we can infer hypotheses about the future based on past observations. These assumptions necessary for generalisation are called inductive biases (Mitchell, 1980).
Generalisation is the goal of supervised machine learning, i.e. achieving low out-of-sample error by learning on a set of training data. When the out-of-sample data is drawn from the same distribution as the training data, this is called interpolation. Hence, it is not surprising that inductive biases play a large role in machine learning.
Choice of inductive bias: Strong vs Weak?
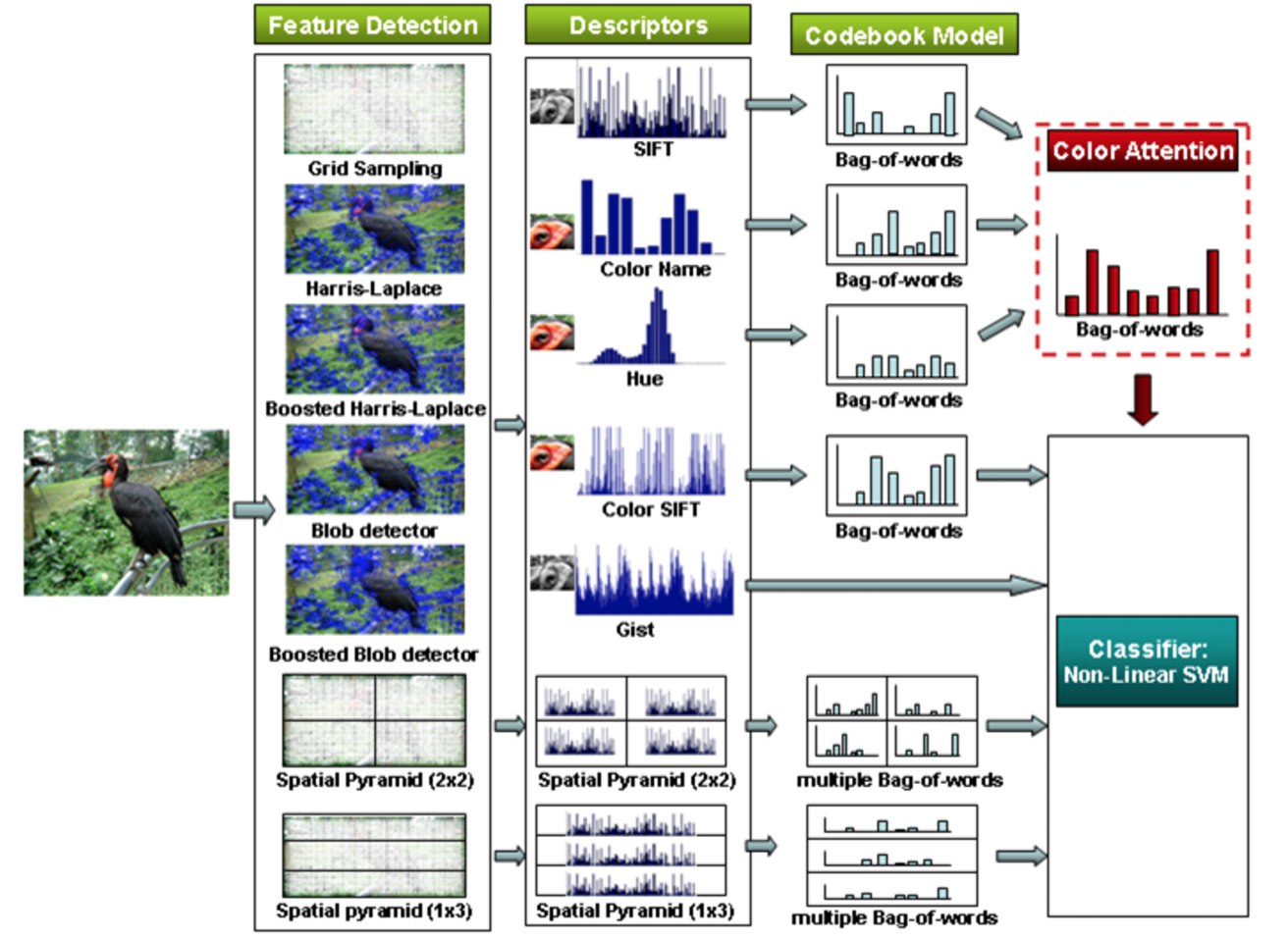 |
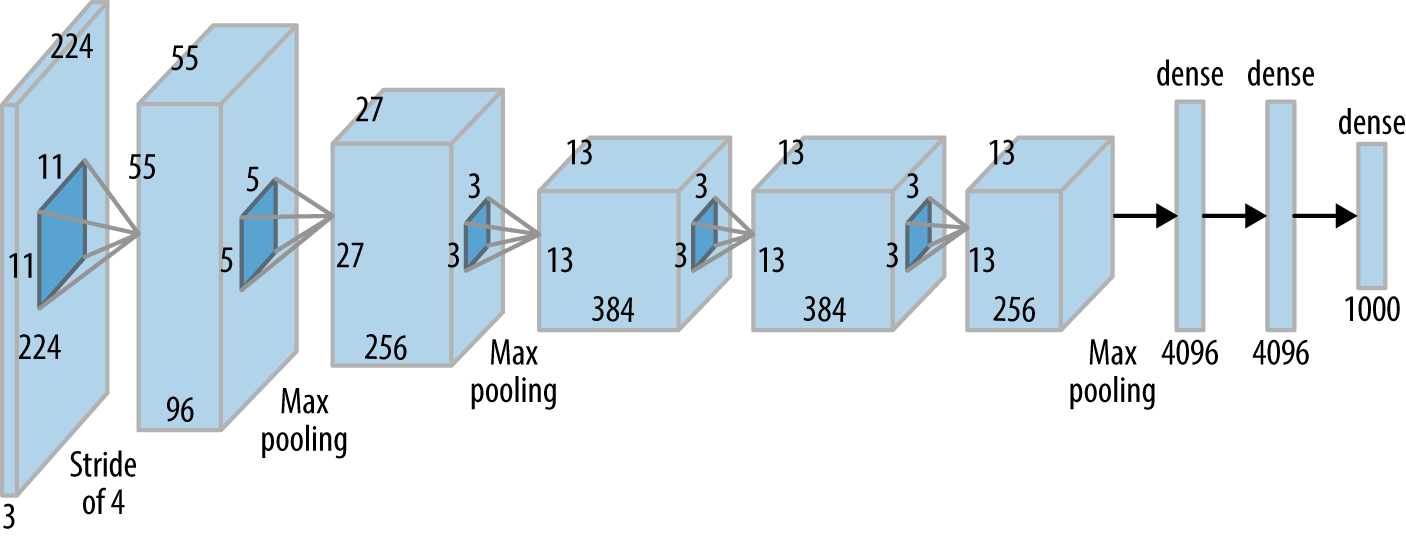 |
|---|---|
| Strong bias: Explicit feature extraction in computer vision tasks. | Weak bias: A convolutional neural network. Feature extraction is not innate, but learned from data. |
Inductive biases come in different flavours: strong vs weak, right vs wrong. While we always want to pick a right inductive bias, the choice between a strong and weak bias is not as clear.
In classical statistical thinking, a strong inductive bias restricts the hypothesis set of function approximators, thereby improving generalisation and increasing sample efficiency. This makes it tempting to introduce strong inductive biases, usually by encoding prior domain knowledge into the innate machinery of the learning process.
However, too much innate structure can actually worsen performance, because it could introduce assumptions that might not be true of real-world and noisy data. For this reason, much of modern machine learning has been transitioned away from the traditional paradigms of rule-based learning and feature extraction.
Inductive biases in machine learning
Every machine learning algorithm has an inductive bias, albeit to varying extents. Every inductive bias constitutes a set of assumptions that require verification. Here are some examples.
| Model / Optimisation | Inductive Bias / Assumption |
|---|---|
| Linear regression | Output variable depends linearly on the inputs |
| SVM | Maximum margin |
| Convolutional neural networks | Translational invariance Local relations between inputs |
| RNN / Attention | Long range dependencies Sequential relations between inputs |
| Graph convolutional networks | Homophily Structural equivalence |
| Deep learning | Distributed representations |
| Regularisation | Regularity / smoothness of a function as measured by a certain function space norm |
| Bidirectionality | Importance of left and right context |
| Multitask learning | Preference for hypotheses that explain more than one task |
Research Directions
Even though inductive biases are widely used in the machine learning, there is great debate about the amount we ought to be incorporating into our learning algorithms (LeCun & Manning on the topic of innate priors). Love them or hate them, inductive biases continue to guide many important research directions.
ML theory through the lens of inductive bias
- Inductive bias of deep convolutional networks through pooling geometry. Cohen & Shashua. ICLR, 2017.
Novel forms of inductive bias
- Attention is all you need. Vaswani et al. NeurIPS, 2017.
- Semi-supervised classification with graph convolutional networks. Kipf & Welling. ICLR, 2017.
- Recursive deep models for semantic compositionality over a sentiment treebank. Socher et al. EMNLP, 2013.
- Long short-term memory. Hochreiter & Schmidhuber. Neural Computation, 1997.
Injection of inductive bias
- Weight agnostic neural networks. Gaier & Ha. NeurIPS, 2019.
- Neural relational inference for interacting systems. Kipf et al. ICML, 2018.
- Deep reinforcement learning with relational inductive biases. Battaglia et al. ICLR, 2019.