Update #5
20 Oct 2018Done
- Experiments with 20 newsgroups and FastText
- Improved experimental flow
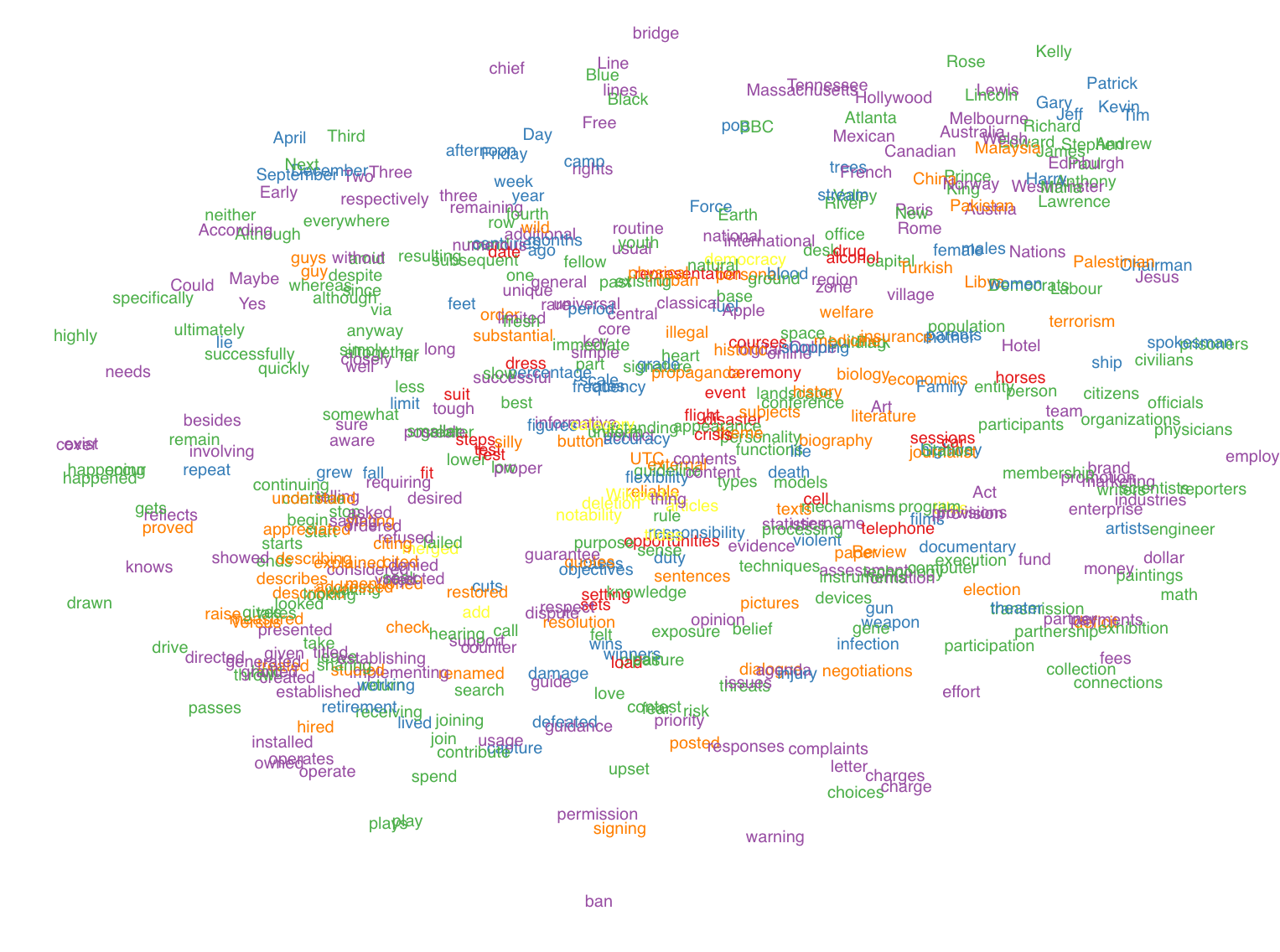
FastText
Each vector is a 300-dimensional word embedding computed in a word2vec model built by Facebook on Wikipedia text. The most common 4,000 English words were used. Stop-words were removed.
Hover over the image on the left for a magnified version.

20 newsgroups
Each vector is a probability distribution of a given document over 20 topics generated by the Latent Dirichlet Allocation (LDA) model. LDA is an unsupervised technique for topic modelling that learns a probability distribution over a bag of words.